HashMap由于查找、添加、删除的性能比较高,几乎是Java中使用频率最高的用于映射(键值对)处理的数据类型。而Java 8中引入红黑树又大程度优化了HashMap的性能。本文结合Java 7和Java 8的区别,探讨一下HashMap的结构实现和常见问题。
介绍
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
HashMap 利用哈希表实现了Map接口,具有以下特性:
- HashMap不保证元素顺序。
- 按照对key进行哈希存储,故不保存插入顺序。
- 由于可能会对元素重新哈希,元素的顺序也会被重新打散,故每次迭代的访问顺序可能不同。
- 该类中的方法未实现同步(与Hashtable不同),有线程安全问题。
- key和value都允许为
null。
如下图所示,HashMap继承了AbstractMap抽象类并且实现了Map接口,

HashMap中有哪些重要参数?
- 初始容量(initialCapacity,默认为16)
- 如果initialCapacity不为2的幂值,HashMap会自动选择比initialCapacity大的下一个2的幂值作为初始容量。
- 在对HashMap进行迭代时,需要遍历整个table以及后面的冲突链表。因此对于迭代比较频繁的场景,不宜将HashMap的初始大小设的过大。
- 对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
- 负载系数(loadFactor,默认为0.75)
当HashMap.size()大于capacity*load_factor时,容器将自动扩容并重新哈希。
HashMap以自定义对象为key时需要注意什么?
- 实现以下两个方法:
- hashCode()方法:决定了对象会被放到哪个bucket里
- equals()方法:当多个对象的哈希值冲突时,决定了这些对象是否是“同一个对象”。
- key的不变性:
- 如果key的值可以被修改,则其hashCode发生了改变,且equals()方法也会判断不是”同一个对象“。Map中就找不到该key对应的Entry对象,从而使得HashMap丢失数据。
实现方式
哈希表一般有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。
Java 7
Java 7中,HashMap采用的是冲突链表方式。

如上图所示,整个HashMap由一个数组和若干个链表组成。
- 称为table的数组大小必须是2的幂值,其索引叫做“桶”(bucket),存储了链表的第一个元素(Entry)。
- 所有具有相同哈希值的键都会被放到同一个链表(桶)中。具有不同哈希值的键最终可能会在相同的桶中。
Entry
Java 7中的HashMap使用了一个内部类Entry< K, V >来存储键值对,并带有两个额外属性:
- next:指向其他Entry的引用,使得HashMap可以存储类似单向链表的数据结构。
- hash:存储键的哈希值,避免重复计算。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
…
}
方法剖析
get()
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是get(Object key)方法的核心。
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key); //key为null的Entry存储在table[0]
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
getEntry()首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。
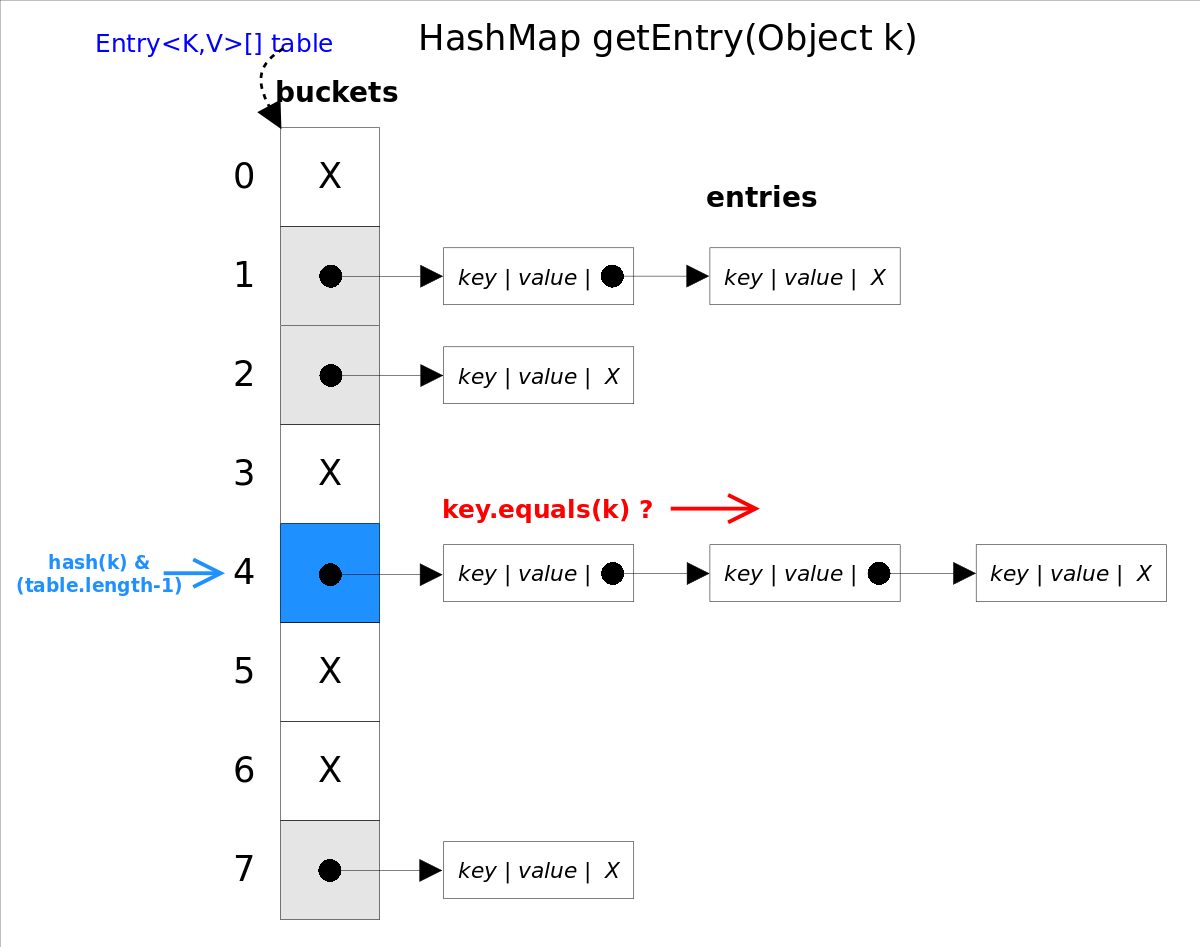
上图中hash(k)&(table.length-1)等价于hash(k)%table.length,原因是HashMap要求table.length必须是2的幂值,因此table.length-1就是二进制低位全是1,跟hash(k)相与会将哈希值的高位全抹掉,剩下的就是余数了。
put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则替换old value,查找过程类似于getEntry()方法。
如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式为头插法。
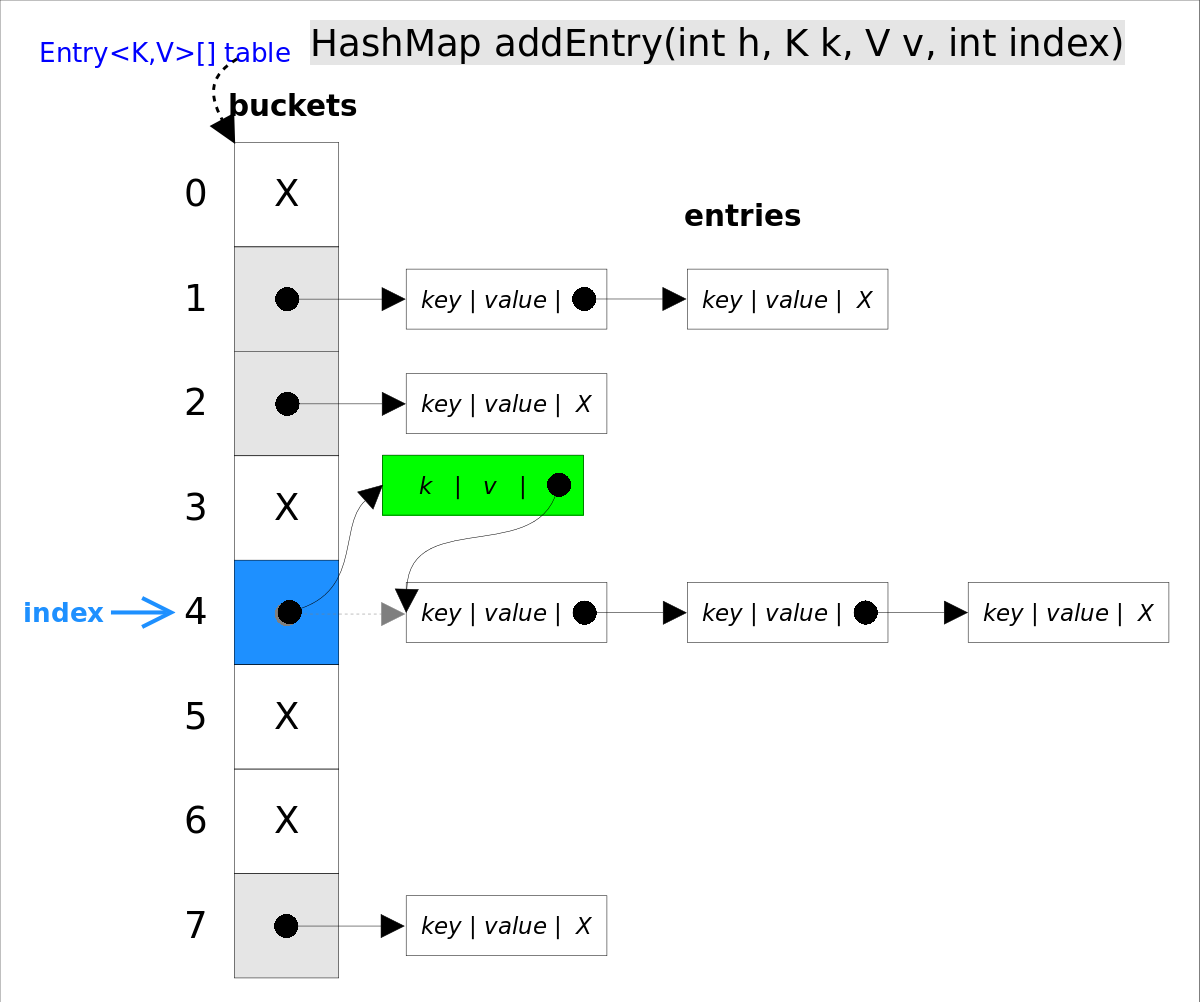
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
最后检查增加一个元素后的Map大小是否大于阀值,如果大于阀值,它会创建一个新的数组,数组长度是当前内部数组的两倍,并且将所有现存Entry对象重新分配到桶上。
- 调整数组大小的目标在于降低链表的大小,从而降低put()、remove()和get()方法的执行时间。
- 对于具有相同哈希值的键所对应的所有Entry对象来说,它们 会在调整大小后分配到相同的桶中。
- 如果两个Entry对象的键的哈希值不一样,但它们之前在同一个桶上,那么在调整以后,并不能保证它们依然在同一 个桶上。
- 扩容时仍是重新计算hash值,在JDK 8中有所改进。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟getEntry()过程类似。

final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}
Java 8
在Java 8中,整个HashMap一开始也是由一个数组和链表组成。键值对被保存在Node对象中。如果某个桶对应的链表长度超过8,将被转换为红黑树结构。因此,HashMap是由一个数组和若干个链表、红黑树组成的。
Node
Node对象包含了和之前Entry对象一样的信息。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
Node可以被扩展成TreeNode。
- 对于内部表中的指定索引(桶),如果node的数目多于8个,那么链表就会被转换成红黑树。
- 对于内部表中的指定索引(桶),如果node的数目小于6个,那么红黑树就会被转换成链表。
TreeNode
TreeNode是一个红黑树的数据结构。红黑树是自平衡的二叉搜索树。它的内部机制可以保证它的高度总是log(n)。
扩容机制
使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
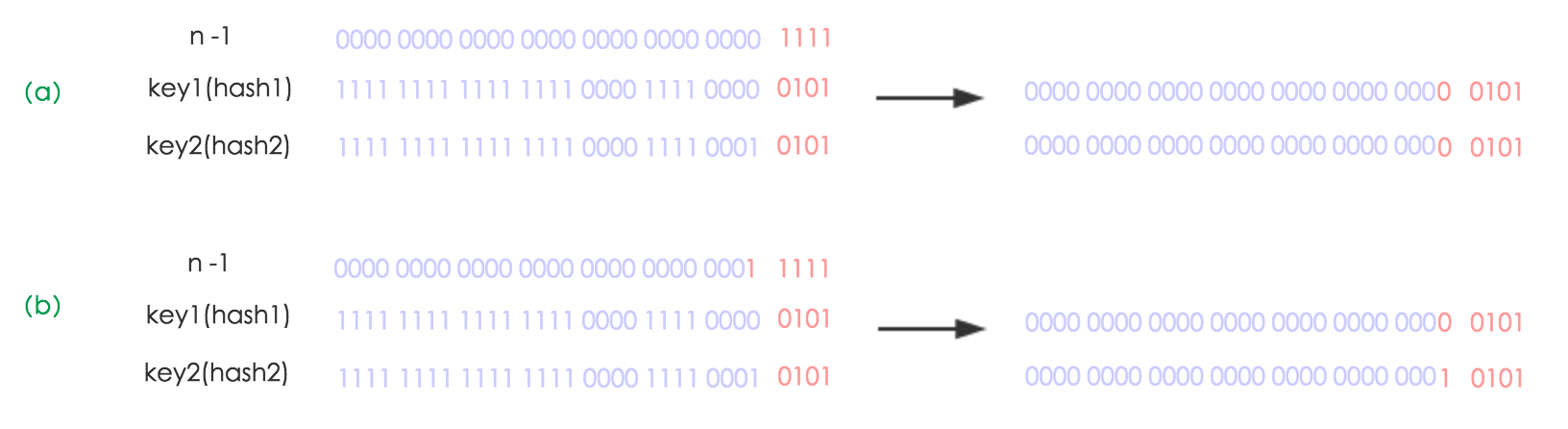
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
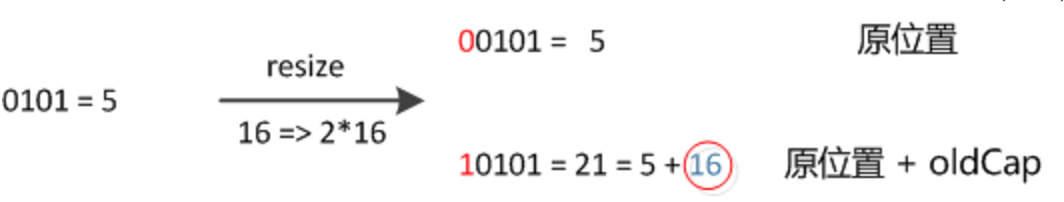
因此在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCapacity”。
常见问题
延迟加载
从Java 7开始,HashMap采用了延迟加载的机制。这意味着即使你为HashMap指定了大小,在我们第一次使用put()方法之前,记录使用的内部数组(耗费4*CAPACITY字节)也不会在内存中分配空间。
为什么HashMap不是线程安全的?
在自动调整大小的机制下,如果一个线程在put时触发了resize,此时另一个线程试着去获取一个对象,就可能会使用旧的索引值,从而找不到Entry对象所在的新桶,甚至可能引发Entry链表成环,导致死循环。